
This week: GPT-5.2 for healthcare, new tools from Microsoft.
the hits just keep coming

Poppin’ week in the AI personal health space.
OpenAI released GPT-5.2
Impressive release that hits SOTA in several important areas, like tool-use and vision, but the most exciting part for me is the improvement to long-context reasoning.
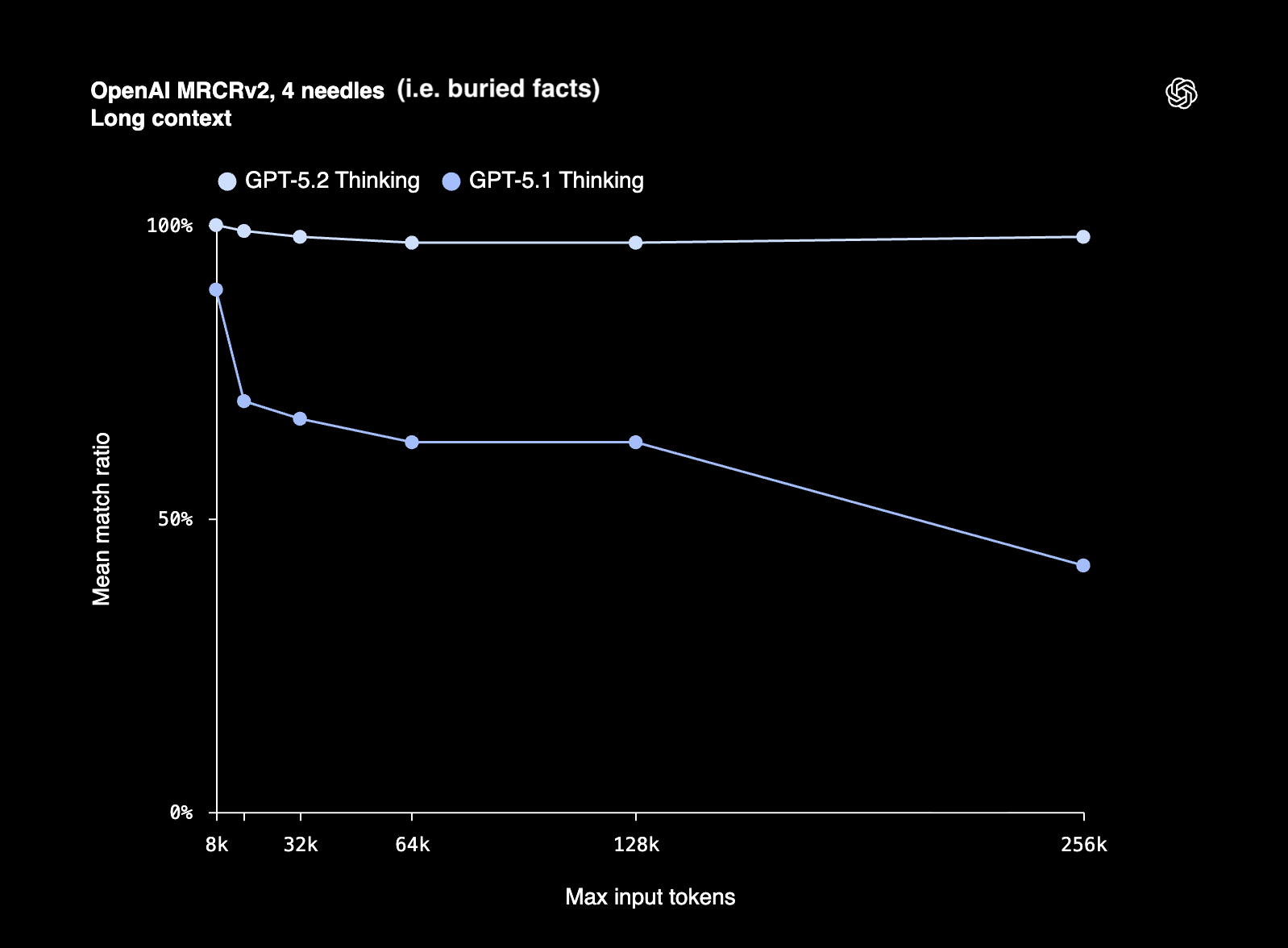
The thing about health data is that there’s usually a lot of it, and my experience with these models is that reasoning and instruction-following abilities tend to drop off once you get halfway through the context window. I’ve already noticed improvements in the 48h I’ve been using 5.2 for coding.
The HealthBench evals are about the same as GPT-5.1, but those are still really good.
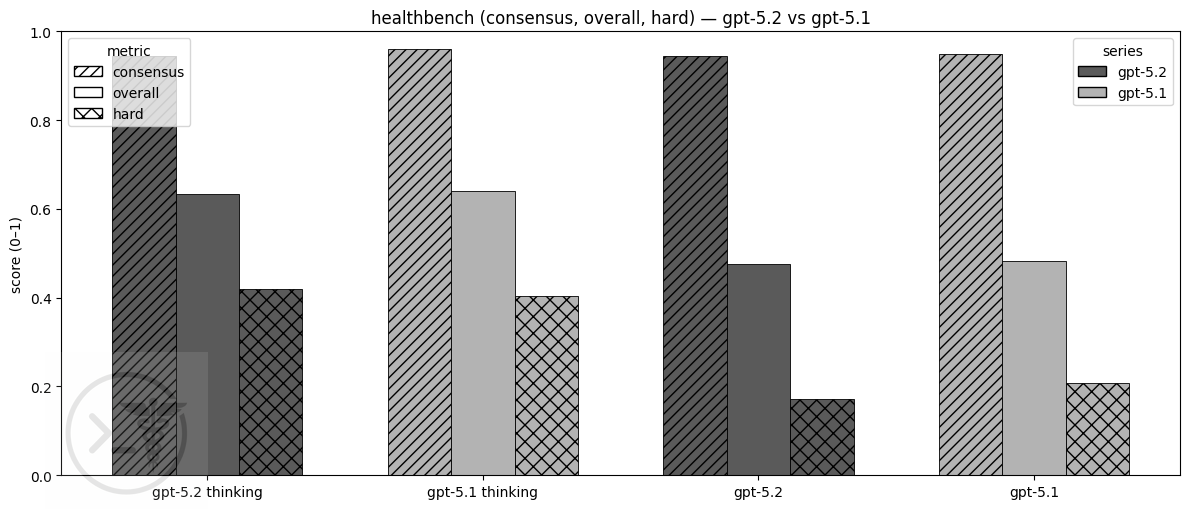
If you’re not familiar with HealthBench, it’s is an eval released by OpenAI earlier this year designed to measure capabilities of AI systems for health. It essentially measures an model’s ability to give good advice in healthcare conversations. Health-related model evals are super interesting and I plan on doing a dedicated post about them soon.
Microsoft releases an open-source evaluation framework for AI models in healthcare: HAIME
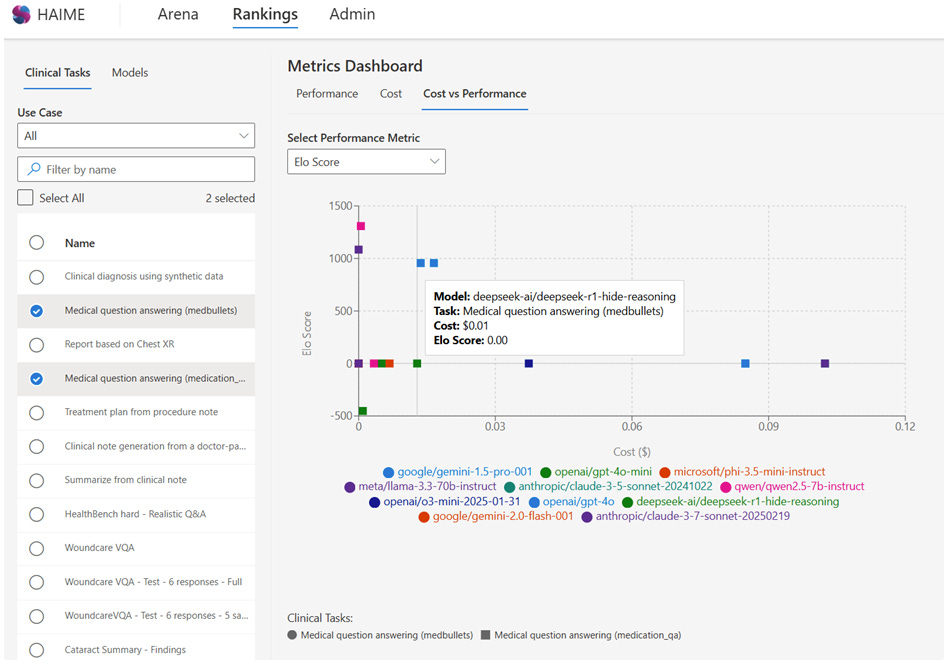
The software seems primarily geared for clinical, non-technical users to evaluate the usefulness of different AI models on real-world health tasks:
“Healthcare AI model evaluator enables healthcare organizations to move beyond vendor promises and generic leaderboards toward data-driven AI adoption decisions. It places the power of evaluation directly in the hands of those who understand clinical needs best—healthcare practitioners themselves.”
Looks really neat - excited to play with it.
Review paper on AI chatbots vs human providers in empathy in patient care
“Your husband’s hangnail is pretty severe. You may want to start making arrangements. I see here he’s designated as an organ donor…” jk jk.
Upshot: Across 15 studies (mostly using GPT-3.5/4), most studies rated llm chatbot responses as more empathic than human clinicians in text-only scenarios, but evidence is mixed. Will be interesting to see how the newer generation models fare here.
Empirical Health releases JETS: a foundation model for processing health data
Impressive work for a small team (3 ppl, I think?) Inspired by Yann LeCun’s JEPA, Joint Embedding for Time Series (JETS) takes inputs of 63 channels of sensor data: heart rate, oxygen saturation, sleep stages, VO2Max, etc. The model was tested on both diagnosis and biomarker prediction tasks. JETS had high accuracy at detecting hypertension (87% AUROC), atrial flutter (70%), ME/CFS (81%), and sick sinus syndrome (87%).
Function Health, a startup that offers lab testing and body scans for early disease detection, raises $300 million in series B (Fierce)
HHS announces AI Strategy
“This infrastructure should emphasize centralization of data and governance to cut costs, reduce duplication, and enable secure, privacy-preserving, AI-ready access to HHS extramural and intramural studies, EHR, claims, cohorts, registries, surveillance, and human services data.”