
This week: Gemini 3 Flash and other new models unlock health use cases
Value compounds as new capabilities get pushed to the model layer

This week, we’ve seen some big leaps forward for AI models that can solve a couple of real-world healthcare pain points for patients:
Patient recall during doctor visits. “Can you remember all that, or do I need to write it down?” The doctor produces a used napkin from his pocket and scribbles illegibly.
Crappy optical data formats. At least a third of inbound docs to healthcare systems are still faxes. A lot of legacy data is still housed as scanned-in PDFs.
While various point solutions exist today, it’s exciting to see new models absorb these capabilities because it means they will become more accessible, better integrated, and cheaper as inference costs continue to fall.
Google releases Gemini 3 Flash
Value for money, this is may be the best model out right now, priced $0.50/1M input tokens, $1/1M audio input tokens and $3/1M output tokens. Even if it’s not the absolute cheapest model for a given task, it’s general multimodal intelligence makes it a great option for solving real problems. To scope ion specifically on the problems mentioned above:
Use 1: Improving patient recall by understanding a recorded doctor-patient conversation.
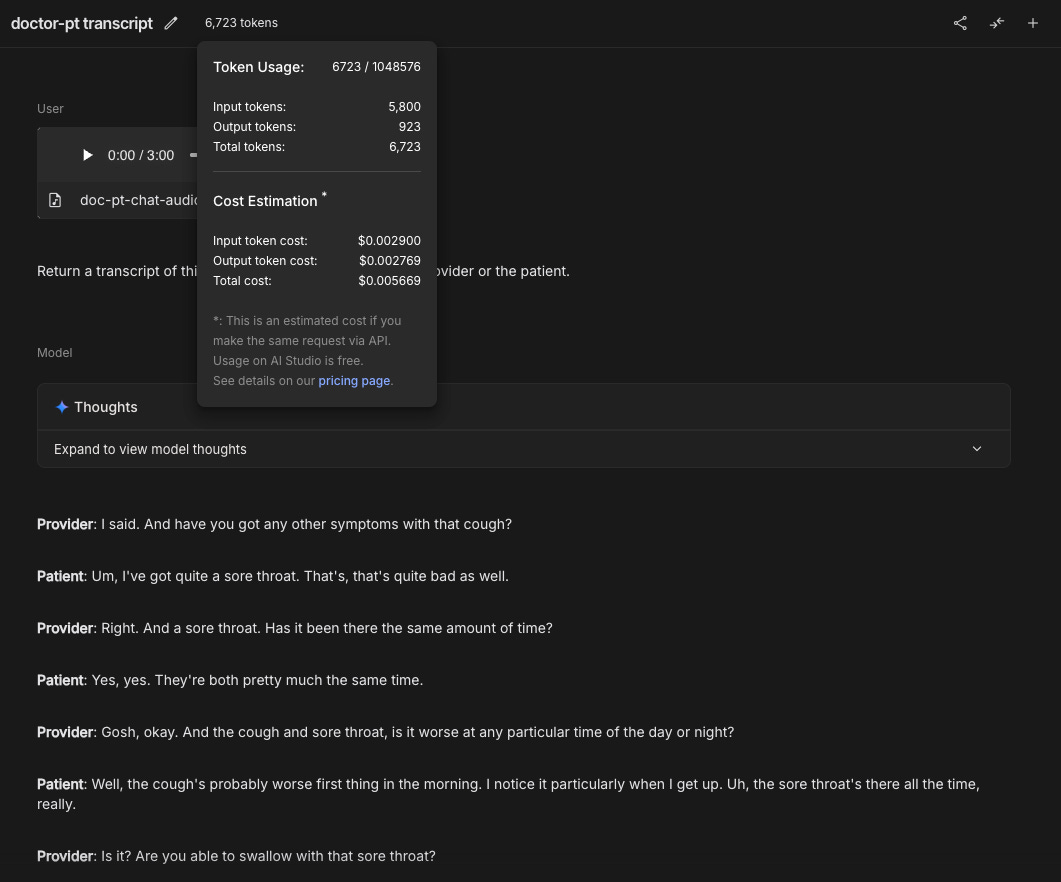
I tried it out with a short example.
Task: Produce a transcript of a 3 minute doctor-patient conversation attributing each turn in the conversation to the doctor or patient.
Result: Perfect transcript, complete with speaker attributions.
Cost: ~6k tokens in. ~1k tokens out. Under 1 cent. Pretty cool.
Use 2: Extracting data from optical formats
By my estimates, Flash 3 would cost between $1.40 - $3 per 1K pages of OCR work, depending on if you use the standard or batch APIs. While that’s more than a competing SOTA OCR model like Mistral OCR 3 (more on that in a minute), you could also leverage Flash 3’s general intelligence, tool call capabilities, and structured outputs to get more bang for your buck on complex tasks. This is where I’d love to know how Flash 3 scores on HealthBench, but I haven’t seen that data out yet.
Mistral releases OCR3
link.
SOTA OCR for $1 / 1K pages. Very impressive.

Google releases open-source MedASR
MedASR was trained on a diverse corpus of de-identified medical speech, comprising approximately 5,000 hours of physician dictations and clinical conversations.
Meta releases SAM Audio
I SAID, I’m prescribing you MEDICAL MARIJUANA!
SAM audio is an open-source model that can segment elements from within audio files. This was previously pretty difficult to do without using proprietary models. I could imagine this being used for voice isolation for recordings of doctor-patient chats with questionable audio quality. Or for isolating your doctor’s voice when he takes your telemed call from Coachella.
A post from NVIDIA on using synthetic LLM data to generate privacy-sensitive datasets for benchmarking, such as patient triage data.
Google Chief Scientist Jeff Dean discussed the moonshot of AI learning from all past medical decisions to improve future ones, a vision that could give patients AI tools for better-informed personal health choices despite privacy challenges.

Resimble AI released Chatterbox Pro, a state-of-the-art open-source TTS model that claims to beat Eleven Labs and Cartesia. It’s fast, open-source and sounds great.

thanks for reading. as always, you can reply back and tell me what you think.