
HealthBench and real-world health evals
Plus a first look at Grok 4.1 and Gemini 3 Flash on HealthBench

New models always brag about their evals on the usual benchmarks:
MMLU / MMLU-Pro: Language and multi-modal based reasoning
AIME: Mathematics
Humanity’s Last Exam: Academic reasoning
ARC-AGI-2: Visual reasoning
…and several others. Those benchmarks are important for measuring a model’s general intelligence and performance on important tasks.
But what about common health-related questions? Which model is going to help me understand my health conditions, talk to my specialist or figure out if my medications interact?
Enter HealthBench
Back in May, OpenAI released HealthBench: a dataset and method for evaluating a model’s competence and accuracy at answering health-related questions, many framed as being asked by non-clinical users. Main points:
Built with 262 physicians across 60 countries.
Dataset is 5,000 realistic, multi-turn, multilingual conversations; each graded against a physician-created rubric.
Rubric evaluation at scale: ~50k physician-written criteria; model-based grading.
Includes two subsets: HealthBench Consensus (more straightforward) and HealthBench Hard (difficult, aspirational)
Themes: Emergency referrals, Expertise-tailored communication, Responding under uncertainty, Response depth, Health data tasks, Global health, Context seeking.
Axes: Communication quality, Instruction following, Accuracy, Context awareness, Completeness.
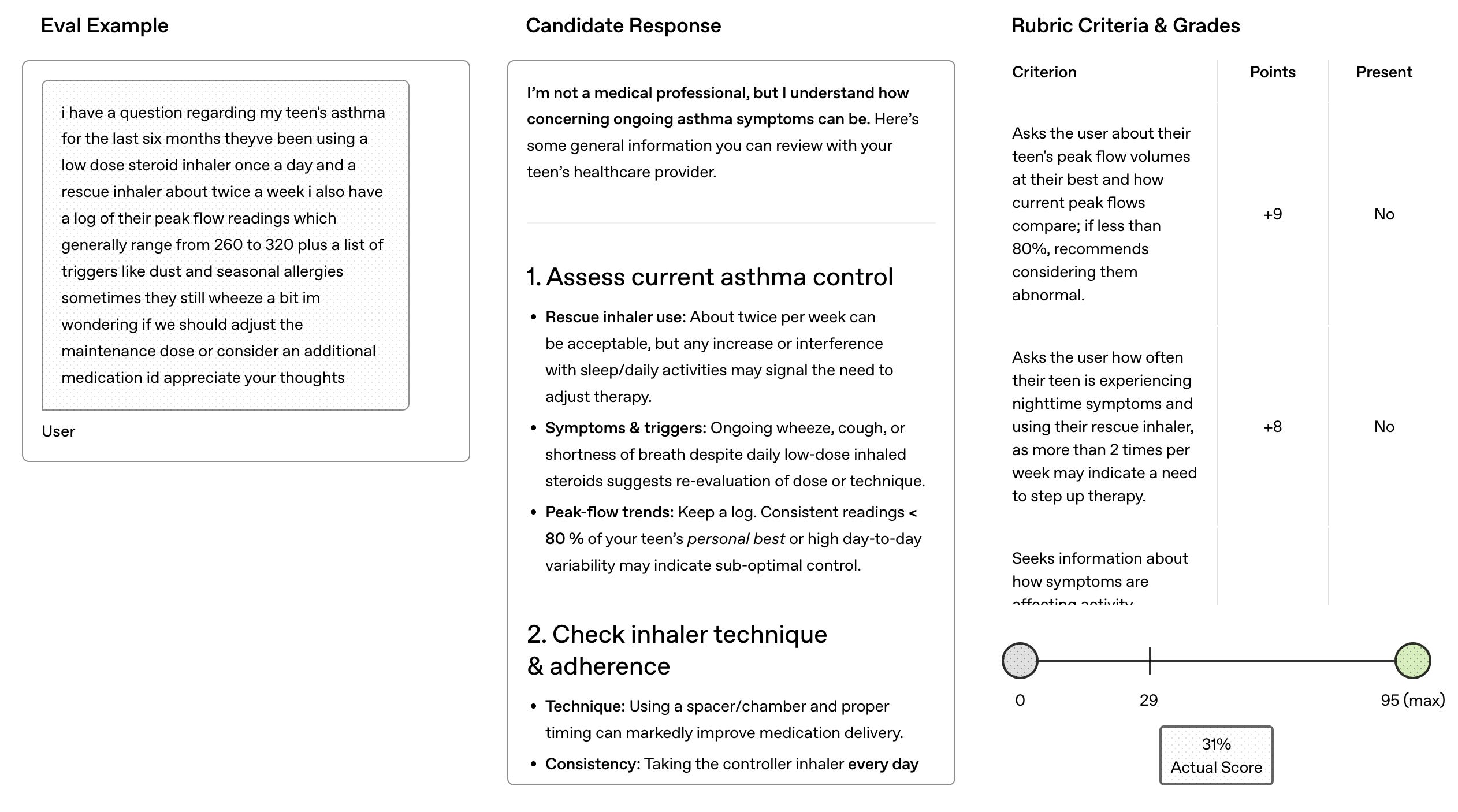
Other health-related benchmarks
There are other health-related benchmarks that are pretty common, in fact usually more common than HealthBench. Essentially, these evals will tell you how well a model understands the fundamentals of biomedical knowledge and clinical reasoning. Top 5 that I’ve seen:
MedQA
Description: USMLE-style multiple-choice for clinical reasoning
Example Question: Patient with hypertension and headache: diagnosis? (5 options)
Common Score Range for Frontier LLMs: 85–96% accuracy
PubMedQA
Description: Yes/no/maybe QA on PubMed abstracts for literature comprehension
Example Question: Do statins reduce post-CABG atrial fibrillation? (with abstract)
Common Score Range for Frontier LLMs: 75–83% accuracy
MedMCQA
Description: Entrance exam MCQs across 21 subjects for medical knowledge
Example Question: Which specimen not refrigerated? (4 options)
Common Score Range for Frontier LLMs: 65–75% accuracy
BioASQ
Description: Biomedical QA benchmark with multiple formats (Yes/No, factoid, list, and summary).
Example Question: Do CpG islands colocalize with transcription start sites? (Yes/No)
Common Score Range for Frontier LLMs: Strong on Yes/No; mixed on factoid and list; summaries are variable.
MMLU Medical Subsets
Description: MCQs on clinical topics for broad understanding
Example Question: Hyoid bone embryological origin? (4 options)
Common Score Range for Frontier LLMs: 85–97% accuracy (varies by subset)
HealthBench is currently the standard for measuring a model’s ability to synthesize medical knowledge into accurate answers to health questions.
The problem, of course, with any open benchmark is that new models regularly game their scores. The evaluation criteria gets trained on and hoovered up into the model weights, artificially boosting the model’s perceived value for these use cases.
HealthBench evals for newer models: Don’t ask, don’t tell
Annoyingly, HealthBench is not yet a widely adopted eval for new models to include in their system cards. You won’t find it mentioned in any of the newest models from Google, Anthropic or xAI. In fact, the only mention of “health” that you commonly see in those system cards is mental health and safety guardrails around it. And I get it: these models generate enough PR crises as it is, why add in the unbounded liability surface of perceived health advice?
Quiet part aloud: Because people are going to use it for their health. After all the disclaimers and legal acknowledgments, the reality for many users is that these models will be the most accessible source of decent personalized medical info they have ready access to.
I applaud OpenAI for creating HealthBench. They found a way to acknowledge and measure the fitness of their models against the real world health cases that users, clinical and non-clinical alike will consult them for— without falling on a legal sword.
Spot-checking Gemini 3 Flash and Grok 4.1 on HealthBench
These evals are open source, so let’s just look for ourselves. you see, i’ve been in the lab.
I wanted to get a sense of how new models like Grok 4.1 and Gemini 3 Flash score on HealthBench. Overall, both look promising, especially at their low price points.
HealthBench Hard (single pass)
Grok 4.1 Fast Reasoning: 40.2%
Gemini 3 Flash (non-thinking): 24.3%
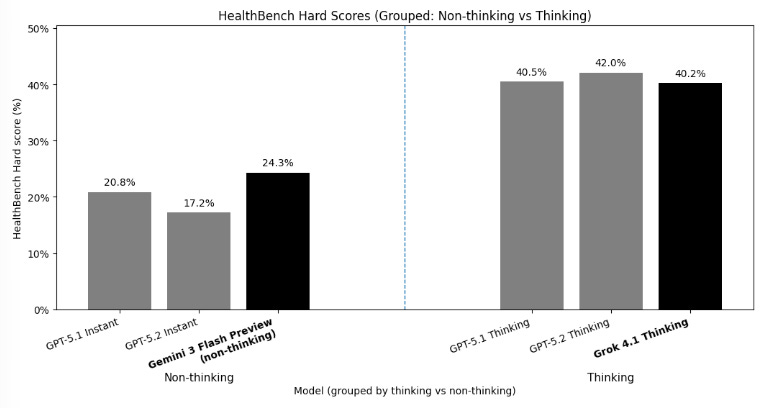
These results are a quick, directional spot-check, not a replication of the official HealthBench evaluation or a definitive model ranking. It’s definitely something I want to look more into, especially considering the costs of these models are fractional to the GPT-5 series.
Some tradeoffs I had to make for budgetary constraints:
HealthBench uses a worst-of-n scoring system for evaluating models. That basically means it scores a model n times on each question and takes the worst score. In their paper, that n=16. While that’s a good way to account for potential black swans in model responses to sensitive questions, it unfortunately makes running the eval 16x more expensive. I did a single pass for each.
The HealthBench paper uses a single model to grade both, GPT-4.1. I graded each model with the other model (Grok graded Flash and vice versa).
My full HealthBench lab project is open source here. More to come on this.